
I am currently a fourth(final)-year Ph.D. Student in the School of Computing, National University of Singapore, advised by Prof. Yang You. Before that, I obtained my master’s and bachelor’s degrees from Northwestern Polytechnical University, China, in 2019 and 2022, respectively. During my master’s study, I was fortunatedly to collaborate with Dr. Nian Liu, under the supervision from Prof. Junwei Han.
My research interest includes Efficient AI, Dynamic Models and Model-system Co-design. I have published more than 20 papers at the top international AI conferences and journals with 
All talents are welcome to send an email (wangbo.zhao96@gmail.com) to me if you are interested in collaborating on projects related to efficient deep learning or other promising research directions.
Beyond research, I am an amateur athlete specializing in the 400 meters (personal best: 53.40) and 400-meter hurdles (personal best: 1:01.78). I was honored to represent NUS in national-level competitions in Singapore and NWPU in provincial-level competitions in Shanxi, China.
🔥 News
- 2026.02: 🎉🎉 Three papers accepted to CVPR 2026, including efficient SAM2, autoregressive video generation, and 3D human avatar modeling!
- 2026.01: 🎉🎉 Four papers accepted to ICLR 2026! Proud of the team’s contributions to efficient DiT, MoE, visual tracking, and generation evaluation. Congratulations to everyone involved! 🚀
- 2026.01: 🎉🎉 One paper accepted to TPAMI 2026. Congratulations to all the authors!
- 2026.01: 🎉🎉 I have successfully completed my thesis defense!
- 2025.11: 🎉🎉 I am invited to give a talk at the the Eastern Institute of Technology and HKUST(GZ).
- 2025.10: 🎉🎉 I am invited to give a talk at the Global College of Shanghai Jiao Tong University.
- 2025.10: 🎉🎉 Recipient of the Google PhD Fellowship 2025 in Machine Learning and ML Foundations.
- 2025.09: 🎉🎉 I am invited to give a talk at ShanghaiTech University.
- 2025.07: 🎉🎉 One paper accepted to ICCV 2025.
- 2025.06: 🎉🎉 I begin my Internship at Meta in Zurich.
- 2025.05: 🎉🎉 One paper accepted to ICML 2025.
- 2025.02: 🎉🎉 One paper accepted to CVPR 2025.
- 2025.01: 🎉🎉 One paper accepted to ICLR 2025.
- 2024.09: 🎉🎉 One paper accepted to NeurIPS 2024.
- 2024.07: 🎉🎉 One paper accepted to ECCV 2024.
📝 Selected Publications
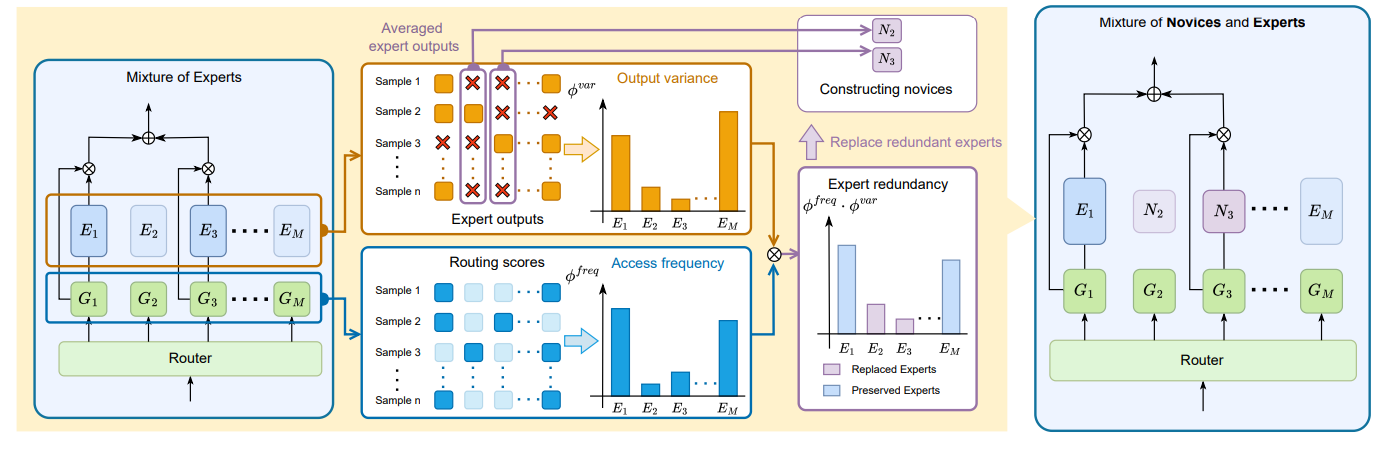
MoNE: Replacing Redundant Experts with Lightweight Novices for Structured Pruning of MoE
Geng Zhang, Yuxuan Han, Yuxuan Lou, Yiqi Zhang, Wangbo Zhao†, Yang You†
- MoNE achieves efficient MoE compression by replacing redundant experts with lightweight “novices,” significantly reducing memory overhead while maintaining higher accuracy than traditional pruning.
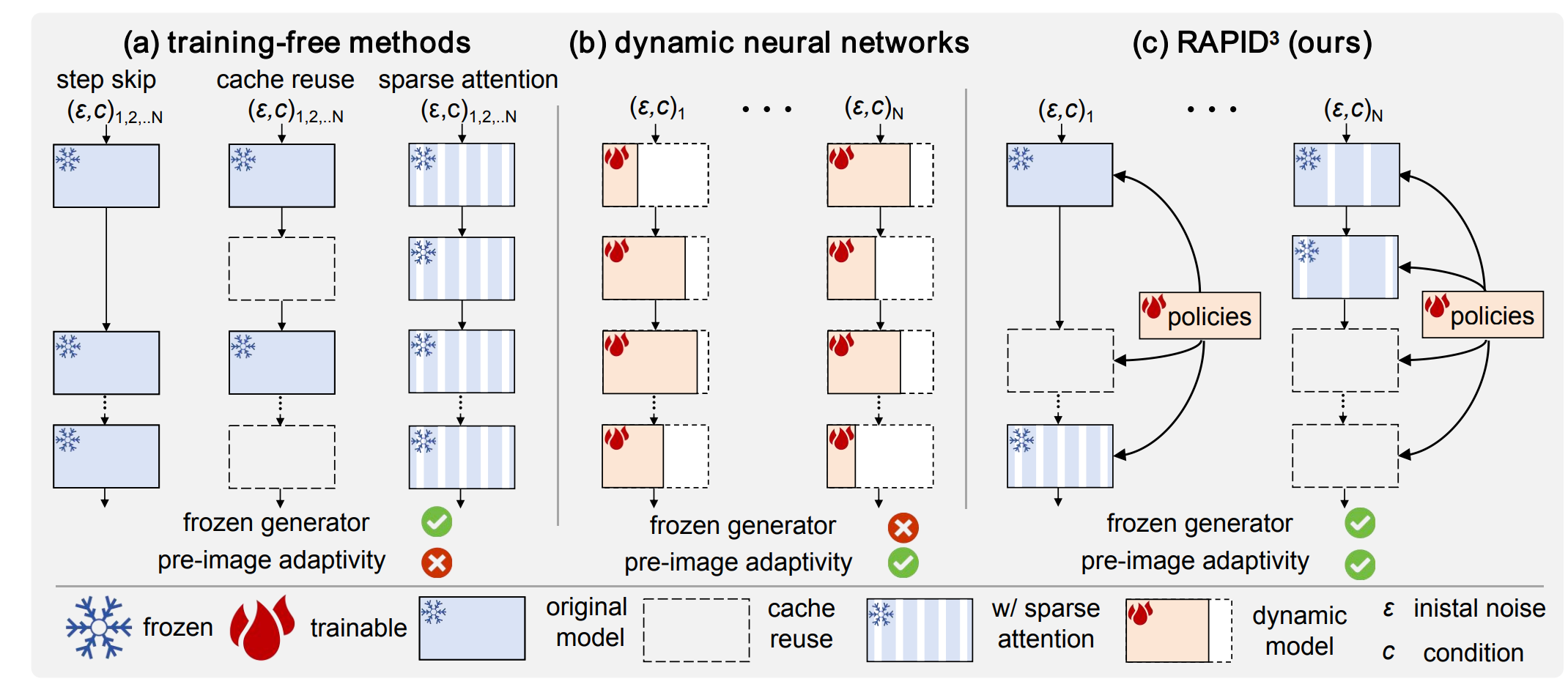
RAPID^3: Tri-Level Reinforced Acceleration Policies for Diffusion Transformer
Wangbo Zhao, Yizeng Han, Zhiwei Tang, Jiasheng Tang, Pengfei Zhou, Kai Wang, Bohan Zhuang, Zhangyang Wang, Fan Wang, Yang You
- RAPID3 speeds up DiT models like FLUX by 3x using adaptive reinforcement learning policies that accelerate sampling without needing any fine-tuning of the original generator.

DyDiT++: Dynamic Diffusion Transformers for Efficient Visual Generation
Wangbo Zhao*, Yizeng Han*, Jiasheng Tang, Kai Wang, Hao Luo, Yibing Song, Gao Huang, Fan Wang, Yang You
- DyDiT++ enhances DyDiT with integration with flow matching for broader applications, improved adaptability to complex tasks, and timestep-based dynamic LoRA for efficient training.
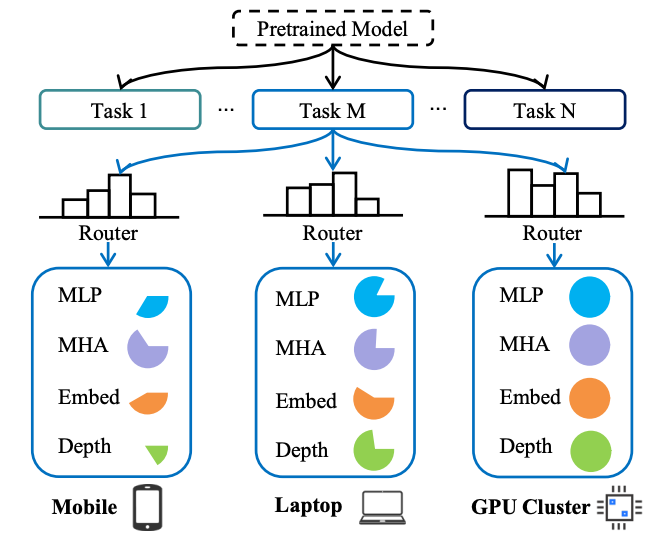
EA-ViT: Efficient Adaptation for Elastic Vision Transformer
Chen Zhu, Wangbo Zhao†, Huiwen Zhang, Samir Khaki, Yuhao Zhou, Weidong Tang, Shuo Wang, Zhihang Yuan, Yuzhang Shang, Xiaojiang Peng, Kai Wang, Dawei Yang†
- EA-ViT is an efficient adaptation framework for Vision Transformers, enabling a single process to generate flexible models of varying sizes for diverse resource constraints, using a nested elastic architecture and a lightweight router optimized with Pareto-optimal configurations.
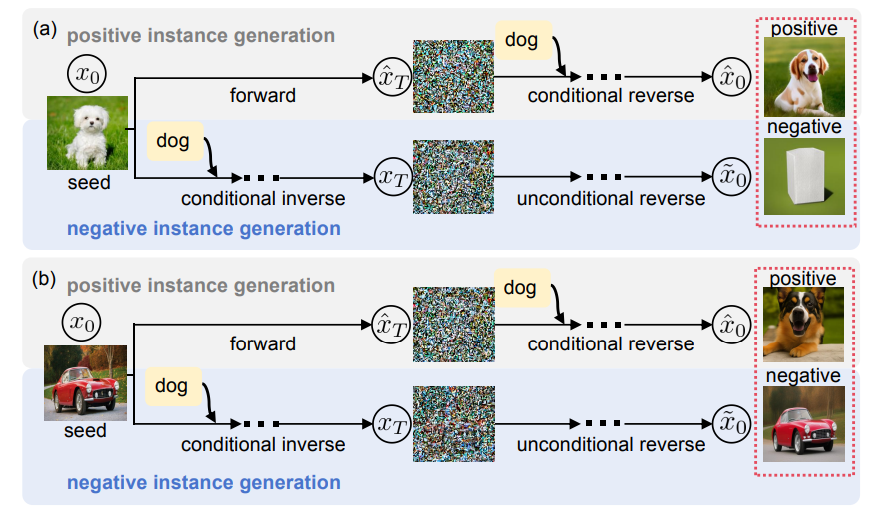
Unsupervised Learning for Class Distribution Mismatch
Pan Du, Wangbo Zhao†, Xinai Lu, Nian Liu, Zhikai Li, Chaoyu Gong, Suyun Zhao†, Hong Chen, Cuiping Li, Kai Wang, Yang You
- UCDM addresses Class Distribution Mismatch (CDM) by leveraging unlabeled data to train classifiers through positive-negative pairs, synthesized using a diffusion model, and a confidence-based pseudo-labeling mechanism, achieving superior performance over semi-supervised methods without relying on labeled data.
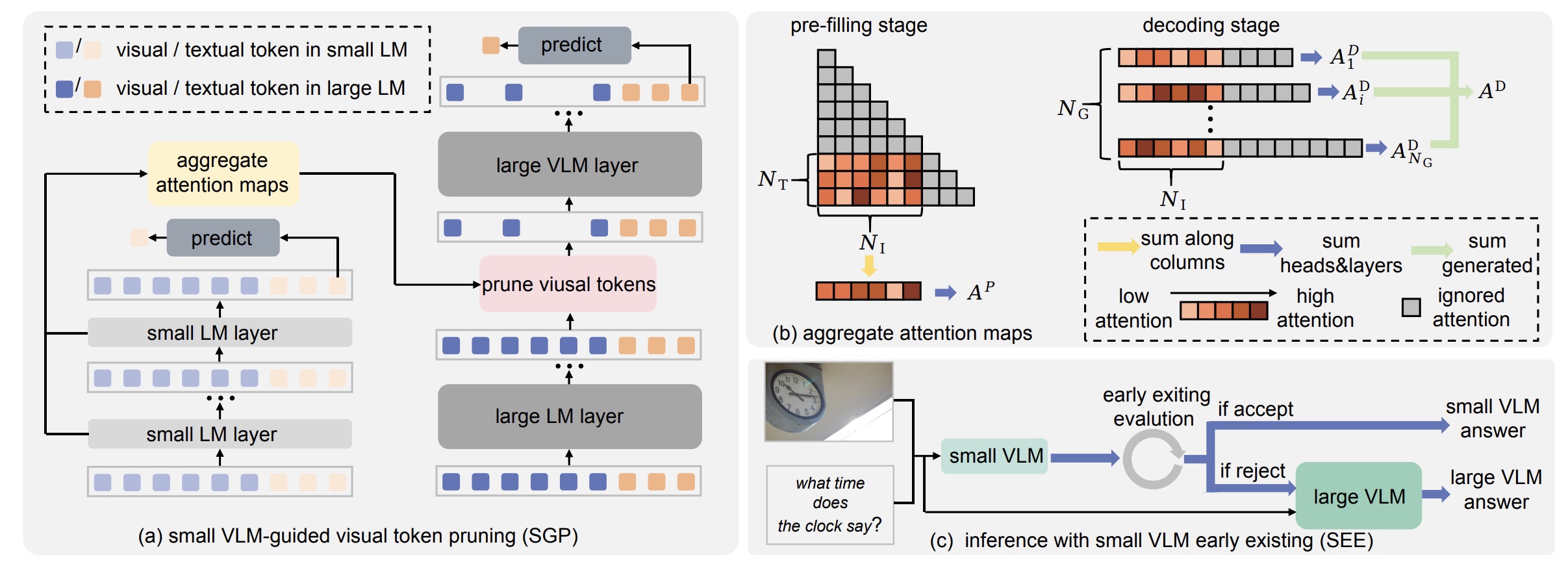
A Stitch in Time Saves Nine: Small VLM is a Precise Guidance for Accelerating Large VLMs
Wangbo Zhao, Yizeng Han, Jiasheng Tang, Zhikai Li, Yibing Song, Kai Wang, Zhangyang Wang, Yang You
- We employ the attention map aggregated from a small VLM to guide visual token pruning in a large VLM. And an early exiting mechanism is developed to fully use the small VLM’s predictions, dynamically invoking the larger VLM only when necessary, yielding a superior trade-off between accuracy and computation.
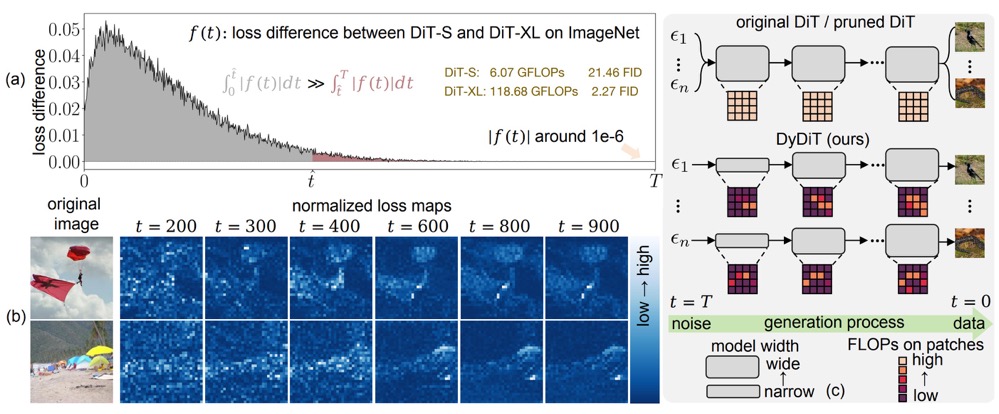
Wangbo Zhao, Yizeng Han, Jiasheng Tang, Kai Wang, Yibing Song, Gao Huang, Fan Wang, Yang You
- We propose to dynamically adjust the computation of DiT in different timesteps and spatial locations of images. The computation of DiT-XL could be saved by 50% without sacrificing generation quality.
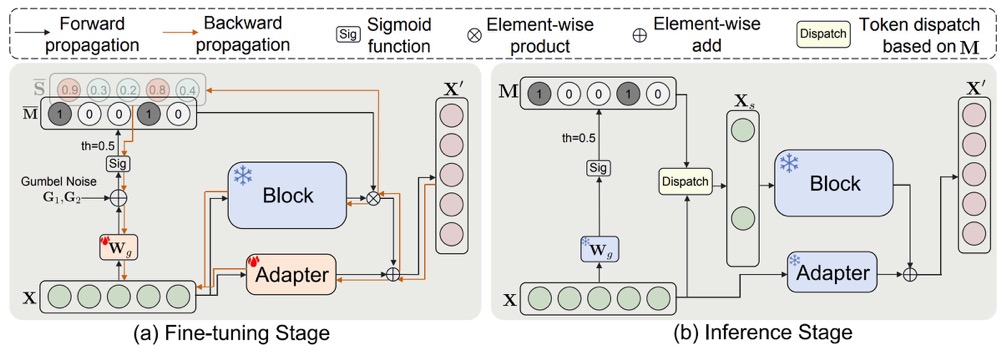
Dynamic Tuning Towards Parameter and Inference Efficiency for ViT Adaptation
Wangbo Zhao, Jiasheng Tang, Yizeng Han, Yibing Song, Kai Wang, Gao Huang, Fan Wang, Yang You
- We propose to adapt static ViT to dynamic ViT via parameter-efficient fine-tuning without full-parameter tuning.
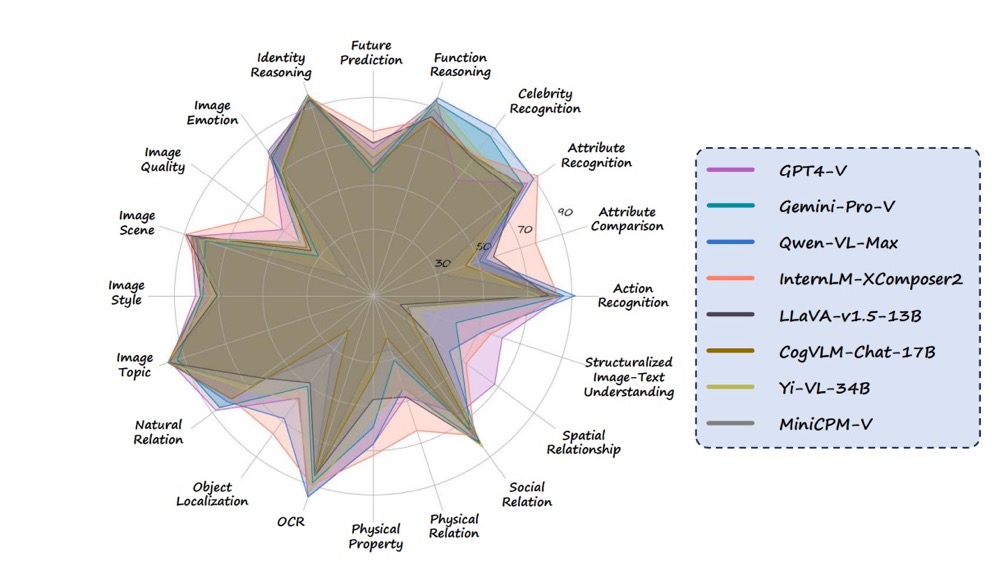
Mmbench: Is your multi-modal model an all-around player?
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, Kai Chen, Dahua Lin
- We propose MMBench, a bilingual benchmark for assessing the multi-modal capabilities of VLMs.
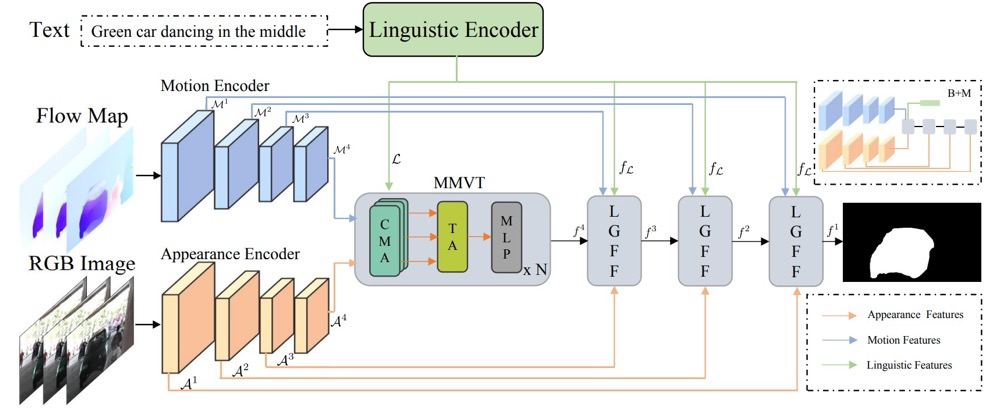
Modeling motion with multi-modal features for text-based video segmentation
Wangbo Zhao, Kai Wang, Xiangxiang Chu, Fuzhao Xue, Xinchao Wang, Yang You
- We design a method to fuse and align appearance, motion, and linguistic features to achieve accurate text-based video segmentation.
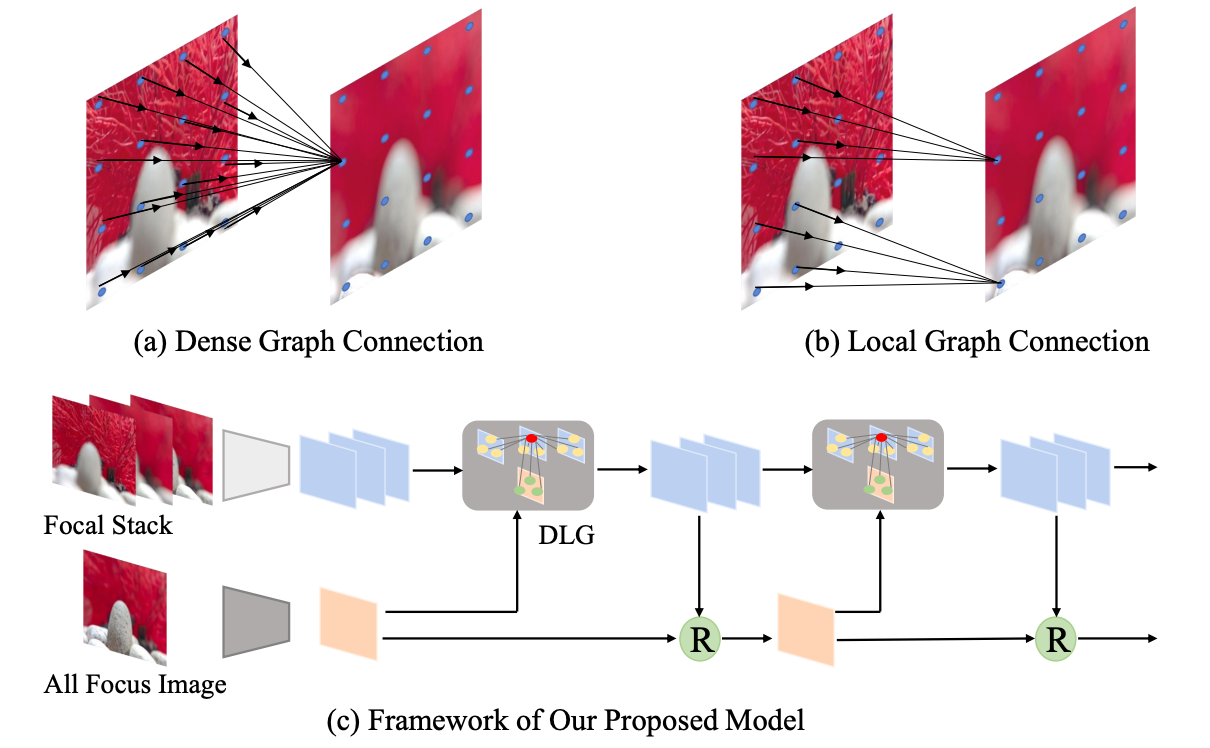
Light field saliency detection with dual local graph learning and reciprocative guidance
Nian Liu*, Wangbo Zhao*, Dingwen Zhang, Junwei Han, Ling Shao
- We introduce a reciprocative guidance scheme for light field saliency detection.

Weakly supervised video salient object detection
Wangbo Zhao, Jing Zhang, Long Li, Nick Barnes, Nian Liu, Junwei Han
- We present the first weakly supervised video salient object detection model based on relabeled fixation guided scribble annotations.
📖 Educations
- 2022.08 - 2026.06, Ph.D., School of Computing, National University of Singapore, Singapore.
- 2019.09 - 2022.04, Master, School of Automation, Northwestern Polytechnical University, China
- 2017.07 - 2019.01, Undergraduate, Université de technologie de Troyes, France
- 2015.09 - 2019.06, Undergraduate, Honors College, Northwestern Polytechnical University, China